When Will My Job Start?
Overview
Do you want to know why your job is not running, when it might start, or what you might do to get it to start more quickly?
As part of our attempt to provide answers to these questions, this page discusses how Slurm works in general and how job prioritization works on Savio specifically.
Why is my job not running?¶
There are a variety of reasons your job may not be running. Some of them may prevent your job from ever running. Others are simply reasons why your job is queued and waiting for resources on the system to become available.
We have developed a helper tool called sq that will try to provide user-friendly information on why a job is not (yet) running:
module load sq
sq
By default, sq will show your pending jobs (or recent jobs if there are no pending jobs) with warning/error messages about potentially problematic situations. If there is a potential problem with a job, it will also suggest a solution.
If you want to see both current and past jobs at the same time, you can use the -a flag. The -q flag silences any error messages so you only see the list of jobs. Other command-line options for controlling which jobs to display are described by sq --help.
If you have encountered a case where sq does not adequately explain the problem, please consider opening an issue so that we can improve it!

Some of the reasons that sq may note for why your job has not
started include the following.
Reasons your job might not ever start:
- You submitted to a partition or QoS or for a number of nodes that you don't have access to.
QOSMaxWallDurationPerJobLimit: You submitted with a time limit that is longer than the maximum time possible for a job in a given QoS.QOSMaxNodePerJobLimit: You requested more nodes than allowed for jobs in a given QoS.QOSMinCpuNotSatisfied: You did not request a sufficient number of CPUs for the GPU(s) requested.QOSMinGRES: You requested an invalid GPU type or did not request a specific GPU type, as required insavio3_gpuandsavio4_gpu, or you didn't specify the QoS, as required for FCA usage of A40 and V100 GPUs insavio3_gpu.AssocGrpCPUMinutesLimit: Your FCA does not have enough service units, possibly because the FCA was not renewed at the start of the yearly cycle in June.
Reasons your job might not have started yet:
ReqNodeNotAvail, Reserved for Maintenance: There may be an upcoming downtime on Savio that overlaps with the time it would take to complete your job.QOSGrpCpuLimitorQOSGrpNodeLimit: For condo users, other users in the group may be using the entire allotment of nodes in the condo. For FCA users, the total number of cores or nodes used by FCA jobs in small partitions on which FCA usage is capped at less than the full partition may be at its limit.ResourcesorPriority: There may not be free nodes available (or free cores for partitions allocated per core) at the moment.QOSMaxCpuPerUserLimit: A partition might have a limit on the resources any user can use at a single time (across all the user's jobs). Specifically, onsavio4_gpu, FCA users are limited to at most 16 CPUs at any given time. Given the 4:1 CPU:GPU ratio for the A5000 GPUs in this partition, that corresponds also to a limit of 4 GPUs.- Your job might have started and exited quickly (perhaps because of an error).
You can also use Slurm's commands, such as squeue to try to understand why your job hasn't started (focusing on the "NODELIST(REASON)" column, but in many cases it can be difficult to interpret the output. In addition to the information above, the REASON codes are explained in man squeue.
How the Slurm scheduler works¶
Savio uses the Slurm scheduler to manage jobs and prioritize jobs amongst the many Savio users.
Overview of Slurm¶
Job submission and scheduling on Savio uses the Slurm software. Slurm controls user access to the resources on Savio and manages the queue of pending jobs based on assigning priorities to jobs and trying to optimize how jobs with different resource requirements can be accommodated. Two key features of Slurm are Fairshare and Backfill.
Fairshare¶
Savio uses Slurm's Fairshare system to prioritize amongst jobs in the queue. Fairshare assigns a numerical priority score to each job based on its characteristics. The key components of the score in Savio's Slurm configuration are the QoS (which ensures that condo jobs are prioritized for the resources purchased by a condo) and recent usage (prioritizing groups and users who have not used Savio much recently over those who have). Usage is quantified based on a standard decay schedule with a half-life of 14 days that downweights usage further in the past. Savio uses a Fair Tree algorithm to prioritize usage based on total usage within each FCA.
Backfill¶
The job(s) at the top of the queue have highest priority. However, if Slurm determines it's possible (based on the resources requested and time limits of the jobs in the queue) for jobs lower in the queue to run without increasing the time it would take to start higher-priority jobs, Slurm will run those lower-priority jobs. This is called backfill. In particular, this can occur when Slurm is collecting resources for multi-node jobs. This feature helps smaller jobs to run and prevents large jobs from hogging the system.
Here's an example of how jobs might be scheduled in a cluster with six nodes. Even though the first node is idle at the moment (see the orange-dashed white box at top of the figure), if you submit a one-node job, it will not be able to run if it has a time limit set to be longer than the available time before Slurm anticipates starting a 2-node job on nodes 1 and 2. A one-node job with a sufficiently short time limit would be able to run on node 1.
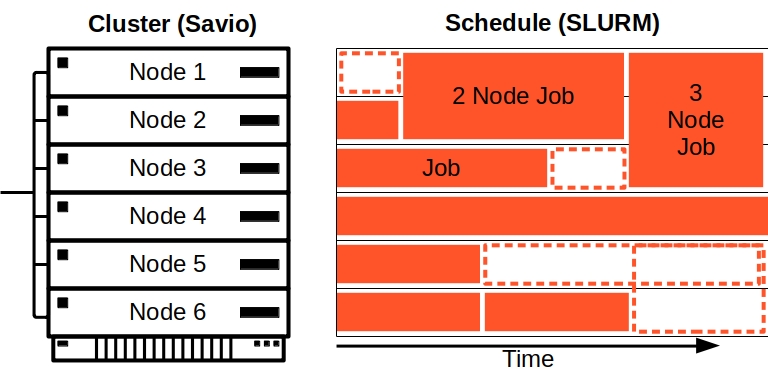
You can increase your odds of being able to take advantage of backfill by requesting less time and fewer nodes.
How priorities and queueing on Savio work¶
Savio has two main ways to run jobs -- under a faculty computing allowance (FCA) and under a condo.
Condos¶
Condo usage, aggregated over all users of the condo, is limited to at most the number of nodes purchased by the condo at any given time. Additional jobs will be queued until usage drops below that limit. The pending jobs will be ordered based on the Slurm Fairshare priority, with users with less recent usage prioritized.
Note that in some circumstances, even when the condo's usage is below the limit, a condo job might not start immediately because the partition is fully used, across all condo and FCA users of the given partition. This can occur when a condo has not been fully used and FCA jobs have filled up the partition during that period of limited usage. Condo jobs are prioritized over FCA jobs in the queue and will start as soon as resources become available. Usually any lag in starting condo jobs under this circumstance is limited.
FCA¶
FCA jobs will start when they reach the top of the queue and resources become available as running jobs finish. The queue is ordered based on the Slurm Fairshare priority (specifically the Fair Tree algorithm. The primary influence on this priority is the overall recent usage by all users in the same FCA as the user submitting the job. Jobs from multiple users within an FCA are then influenced by their individual recent usage.
In more detail, usage at the FCA level (summed across all partitions) is ordered across all FCAs, and the priority for a given job depends inversely on that recent usage (based on the FCA the job is using). Similarly, amongst users within an FCA, usage is ordered amongst those users, such that for a given partition, a user with lower recent usage in that partition will have higher priority than one with higher recent usage.
One can see the Fairshare priority by looking at the FairShare column in the output of this command:
sshare -a
Other columns show the recent usage, which is the main factor influencing the FairShare column. Be sure to look at the usage at the level of the FCA when comparing priority across users in different FCAs.
When will my job start?¶
You can look at the Slurm queue to get a sense for how many other jobs are pending in the relevant partition and where your job is in the queue.
squeue -p <partition_name> --state=PD -l
If you are using a condo, you can check how many other jobs are pending under the condo QoS:
squeue -q <condo_qos> --state=PD
You can see the jobs run by other users in your group by specifying the account name:
squeue -A <account>
You can also ask Slurm to estimate the start time:
squeue -j <jobid> --start
This is only an estimate. Slurm bases this on the time limits provided for all jobs, but in most cases these will not be the actual run times of the jobs.
What can I do to get my job to start more quickly?¶
There are a few things you might be able to do to get your job to start faster.
- Shorten the time limit on your job, if possible. This may allow the scheduler to fit your job into a time window while it is trying to make room for a larger job (using Slurm's backfill functionality).
- Request fewer nodes (or fewer cores on partitions scheduled by core), if possible. This may allow the scheduler to fit your job into a time window while it is trying to make room for a larger job (using Slurm's backfill functionality).
- If you are using an FCA, but you have access to a condo, you might submit to the condo, as condos get higher priority access to a pool of nodes equivalent to those nodes purchased by the condo.
- If you are using a condo and your fellow group members are using the entire pool of condo nodes, you might submit to an FCA instead. The following command may be useful to assess usage within the condo:
squeue -q <condo_qos> - Submit to a partition that is less used. You can use the following command to see how many (if any) idle nodes there are. NOTE: idle nodes may not be available for your job if Slurm is reserving them to accommodate another (multi-node) job.
sinfo -p <partition_name> sinfo -p <partition_name> state=idle - Wait to submit if you or fellow FCA users in your group have submitted many jobs recently under an FCA. Because usage is downweighted over time, as days go by, your priority for any new jobs you submit will increase. However, your priority is affected by other usage in the FCA group, so if other users in your group continue to heavily use the FCA, then your priority may not increase.